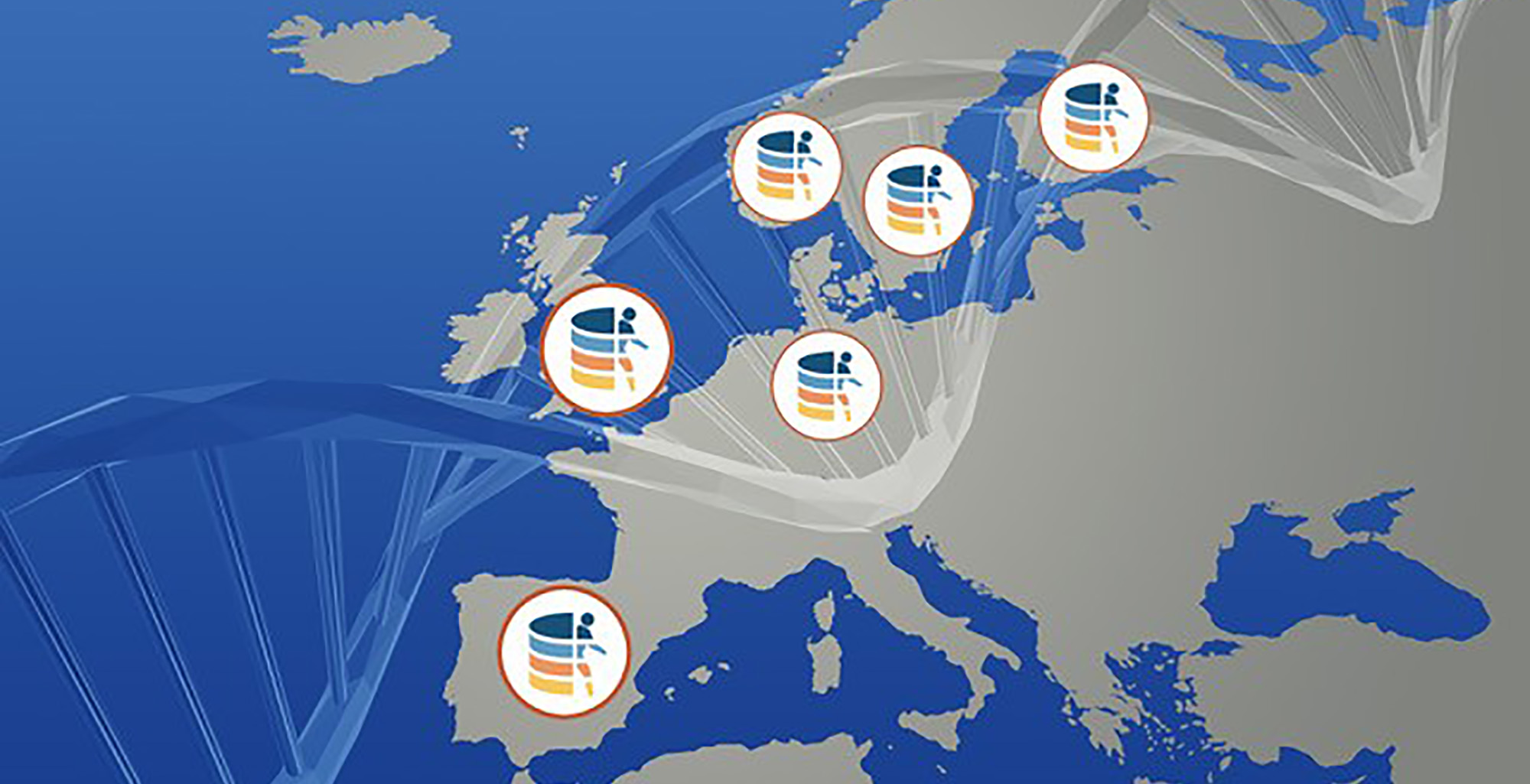
The Federation of European Genome and Phenome Archives (FEGA) has been born, an infrastructure that will facilitate access to genomic data generated in the health systems of, so far, five countries – Spain, Germany, Sweden, Finland and Norway.
FEGA provides a network that allows transnational access to human genomic data for research, rigorously following data protection regulations, such as the new GDPR law. Thus, the federation is made up of ‘nodes’ in research institutes that store and manage data locally and, in turn, share the metadata – information about the characteristics of each data set, such as the ethnicity, age, or health status of participants in a study – so that scientific teams around the world can discover the data and subsequently access and analyze them securely, without the data leaving the country where it was generated.
The data from the Spanish FEGA node will be hosted on the MareNostrum supercomputer at the Barcelona Supercomputing Center – Centro Nacional de Supercomputación (BSC-CNS), which will be a key component in the Precision Medicine strategy of the Spanish National Health System.
In this video you can see how the FEGA will work with its central and local nodes.
FEGA is an evolution of the EGA, the European Genome and Phenome Archive (what would now be the central EGA), which was born at the European Bioinformatics Institute (EMBL-EBI) in the UK and then expanded with the Barcelona Biomedical Research Park (PRBB) site in 2013, managed by the Centre for Genomic Regulation (CRG).
According to Mallory Freeberg, EGA coordinator at EMBL-EBI, this archive “is like a secure search engine for genomic data, helping previously authorized scientific teams to find existing data on the disease they are studying”.
Arcadi Navarro, director of the EGA team at the CRG, agrees. “The goal of EGA is that any researcher can find out if there are studies and data of interest to him or her, anywhere in the world”.
In the following interview, Navarro, also an ICREA research professor, professor at the Universitat Pompeu Fabra (UPF) and a researcher at the Institute of Evolutionary Biology (IBE: CSIC-UPF), tells us why the expansion of this initiative is important and how it has been done.
Until now, the EGA collected genomic data from research projects in different countries in Europe – and even elsewhere in the world. Why has this been ‘decentralized’ and the federation created?
There are three main reasons.
The most important one is a legal reason. Until now, most of the genomic data we had came from research projects where a few volunteers were involved. But now – already today, and in the near future even more – we have more and more data coming from health systems. It is becoming more and more common to sequence a patient’s genome for certain diagnostic tests, for example. And if these patients grant access to their data, these can be very useful for research. But since the genome cannot be 100% anonymized (it is unique to each person!), it is very sensitive data, so each country must legislate what to do with these data and how to treat them. And in some cases, this legislation means that the data must be kept within the country itself. Therefore, although we may have data in EGA that comes from Finnish research projects, for example, we could not have data from the Finnish health system; it must be managed and stored in a Finnish database.
“There is no way to completely anonymize the genome, so genomic data are very sensitive and require highly regulated control”
Arcadi Navarro (EGA-CRG, UPF, IBE)
Does this make the central EGA less valuable?
No, not at all. This federation means that all the data are linked and, in fact, they can all be reached through the central EGA. I mean, at the user level, you don’t even know where the data comes from. You go on the EGA website, search for the datasets you are interested in, and ask for access, which is obviously tightly controlled. This access will first be managed by EGA central (through the CRG and the EBI). Next, if the data come from a research project, access will be controlled by one of the more than 1,500 data access committees (some institutions have a single committee for all the data they generate, others have specific committees for each project). And if they come from health systems, or for any data that requires it for whatever reason, access will be managed by the local database at the country of origin.
Also, it’s in everyone’s interest having the data distributed and managed from different places, because the EGA is a free but very expensive service (we are able to run it here thanks to grants from ‘la Caixa’ Foundation and Carlos III Health Institute). And, the the way it is growing, this network will make it more sustainable. So this is the second reason for this federation, a practical reason.
And the third reason?
The third one is a strategic reason. Those of us who are managing the EGA see every day the challenges that this poses, and also how important these resources are. Although there are thousands of people using it, there are only about 60 of us (30 here and 30 in the UK) who see this reality behind the scences. It’s good for us that there are many more people in more institutions seeing the problem from the inside! This helps to raise awareness, to have voices in different countries explaining to authorities, funding agencies, etc. that these data sharing is fundamental for science to move forward and it needs investment.
“Science is a project of all humanity”
These 5 countries are the first in the federation. Do you intend to expand it?
Of course! And not only with European countries. We have already been contacted from Argentina, Canada, South Africa and Australia, saying they want to be part of FEGA. And if they meet our requirements for reliability, security, quality, etc. and follow certain standards so that the data is interoperable and comparable with others, we will be delighted to have them join in.
In the end we all want the same thing: to generate more genomic data from all over the world (from different populations) and that these become linked and accessible to the largest number of researchers, in order to advance faster in prevention, diagnosis, drug development and new personalized therapies… Because science is a project of all humanity.