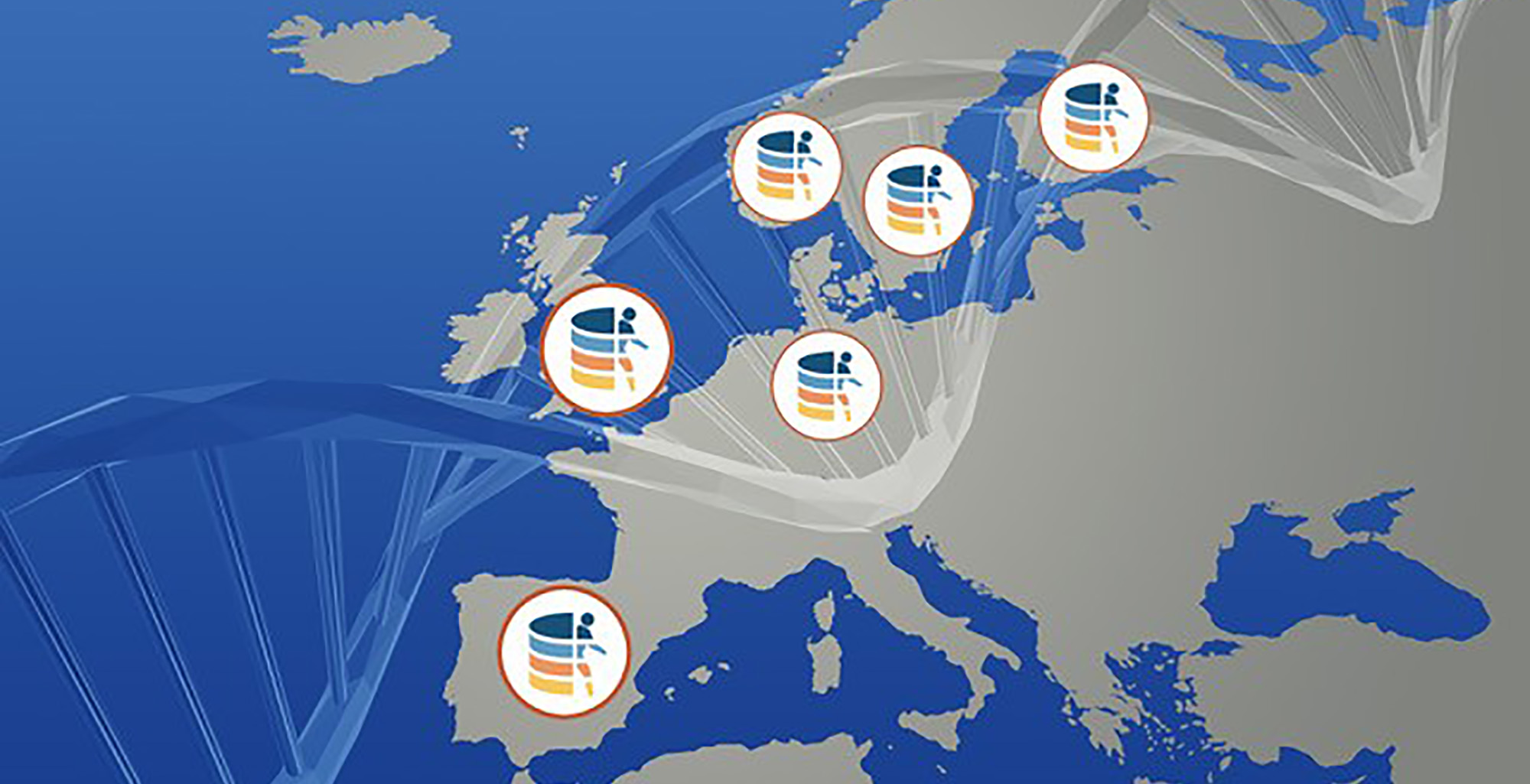
Ha nascut la Federació d’Arxius Europeus de Genomes i Fenomes (FEGA), una infraestructura que facilitarà l’accés al personal investigador a dades genòmiques generades als sistemes de salut de, de moment, cinc països – Espanya, Alemanya, Suècia, Finlàndia i Noruega.
La FEGA proporciona una xarxa que permet l’accés transnacional a dades genòmiques humanes per a la recerca, seguint amb rigor les normatives de protecció de dades, com la nova llei GDPR. Així, la federació està formada per ‘nodes’ en instituts de recerca que emmagatzemen i administren dades localment i, alhora, comparteixen les metadades – la informació sobre les característiques de cada conjunt de dades, com l’ètnia, l’edat o l’estat de salut dels participants en un estudi – per tal que equips científics de tot el món descobreixin les dades i posteriorment hi puguin accedir i analitzar-les de manera segura, sense que aquestes surtin del país on es varen generar.
Les dades del node espanyol d’EGA s’albergaran al supercomputador MareNostrum del Barcelona Supercomputing Center – Centro Nacional de Supercomputación (BSC-CNS), que serà un component clau en l’estratègia de Medicina de Precisió del Sistema Nacional de Salut d’Espanya.
FEGA és una evolució de l’EGA, l’Arxiu Europeu de Genomes i Fenomes (el que ara seria l’EGA central), que va nèixer a l’European Bioinformatics Institute (EMBL-EBI) al Regne Unit i es va ampliar amb la seu del Parc de Recerca Biomèdica de Barcelona (PRBB) l’any 2013, gestionada pel Centre de Regulació Genòmica (CRG).
Segons Mallory Freeberg, coordinadora de l’EGA a l’EMBL-EBI, aquesta arxiu “és com un motor de cerca segur de dades genòmiques, que ajuda a equips científics prèviament autoritzats a trobar dades existents sobre la malaltia que estan estudiant”.
Arcadi Navarro, director de l’equip EGA al Centre de Regulació Genòmica (CRG), hi està d’acord. “L’objectiu d’EGA és que qualsevol investigador o investigadora pugui saber si existeixen estudis i dades del seu interés, a qualsevol lloc del món”.
El també professor d’investigació ICREA, professor de la Universitat Pompeu Fabra (UPF) i investigador a l’Institut de Biologia Evolutiva (IBE: CSIC-UPF) ens explica el perquè i el com de l’ampliació d’aquesta important iniciativa.
Fins ara l’EGA recollia dades genòmiques de projectes de recerca de diferents països d’Europa – i fins i tot d’altres llocs del món. Per què s’ha ‘descentralitzat’ i creat aquesta federació?
Hi ha tres motius principals.
El motiu més important és legal. Fins ara la majoria de dades genòmiques que teníem provenien de projectes de recerca on unes quantes persones voluntàries hi participaven. Però ara – ja avui, i en un futur proper encara més – tenim més i més dades que provenen dels sistemes de salut. Cada vegada és més comú seqüenciar el genoma d’un pacient per determinades proves de diagnòstic, per exemple. I si aquests pacients hi accedeixen, aquestes dades poden ser molt útils per a la recerca. Però com que el genoma no es pot anonimizar de forma absoluta (al cap i a la fi és únic per cada persona!), són dades molt sensibles, pel que cada país ha de legislar què fer amb aquestes dades i com. I en alguns casos, aquesta legislació implica que les dades s’han de custodiar dins el propi país. Per tant, tot i que a EGA podem tenir dades provinents de projectes de recerca de Finlàndia, per exemple, no podríem tenir dades del sistema de salut finlandés; aquestes hauran de custodiar-se i gestionar-se a una base de dades finlandesa.
“No hi ha manera d’anonimitzar completament el genoma, per tant les dades genòmiques són molt sensibles i requereixen d’un control molt regulat”
Arcadi Navarro (EGA-CRG, UPF, IBE)
Això fa perdre valor a l’EGA central?
No, de cap manera. Aquesta federació vol dir que totes les dades estan vinculades, i de fet, s’hi pot arribar a totes a través d’EGA central. És a dir, a nivell d’usuari, ni tan sols saps d’on estan venint les dades. Tu entres a la web d’EGA, busques els conjunts de dades que t’interessen, i hi demanes accés, que està òbviament molt controlat. Aquest accés estarà gestionat primer per EGA central (a través del CRG i l’EBI). A continuació, l’accés estarà controlat per un dels més de 1.500 comités d’accés a les dades (algunes institucions en tenen un únic per totes les dades que generen, d’altres tenen comités específics per cada projecte). I si venen dels sistemes de salut, o aquells que ho precisin per qualsevol motiu, l’accés estarà gestionat per la seu local del propi país d’origen.
A més, a tothom ens interessa que les dades estiguin distribuïdes i es gestionin des de diversos llocs, perquè l’EGA és un servei gratuït però molt costós (possible aquí gràcies als ajuts de la Fundació ‘la Caixa’ i l’Instituto de Salud Carlos III), i amb el que està creixent, aquesta xarxa farà que sigui més sostenible. Per tant, aquest és el segon motiu per aquesta federació, un motiu pràctic.
I el tercer motiu?
El tercer és un motiu estratègic. Les persones que estem gestionant l’EGA veiem cada dia els reptes que això suposa, i també la grandíssima importància que té. Però tot i que hi ha milers de persones que en fan ús, som només unes 60 (30 aquí i 30 al Regne Unit) les que veiem aquesta realitat. Ja ens va bé que hi hagi moltes més persones a més institucions veient el problema des de dins! Això ajuda a crear consciència, a que hi hagi veus a diferents països explicant a les autoritats, les agències financiadores, etc. que el compartir dades és una qüestió fonamental per a que avanci la ciència.
“La ciència és un projecte de tota la humanitat”
Aquests 5 països han estat els primers de la federació – hi ha intencions d’ampliar més?
I tant! I no tan sols a Europa. Ja ens han contactat d’Argentina, de Canadà, de SudÀfrica i d’Austràlia dient que volen ser part de FEGA. I si compleixen els nostres requisits de fiabilitat, seguretat, qualitat, etc. i segueixen certs standards per tal que les dades siguin interoperatives i comparables amb d’altres, estem encantats que s’hi uneixin.
Al final tots volem el mateix: generar més dades genòmiques d’arreu del món (de diferents poblacions) i que aquestes estiguin vinculades i accessibles al major nombre d’investigadors i investigadores, per tal d’avançar més ràpid en la prevenció, el diagnòstic, el desenvolupament de fàrmacs i noves teràpies personalitzades… Perquè la ciència és un projecte de tota la humanitat.