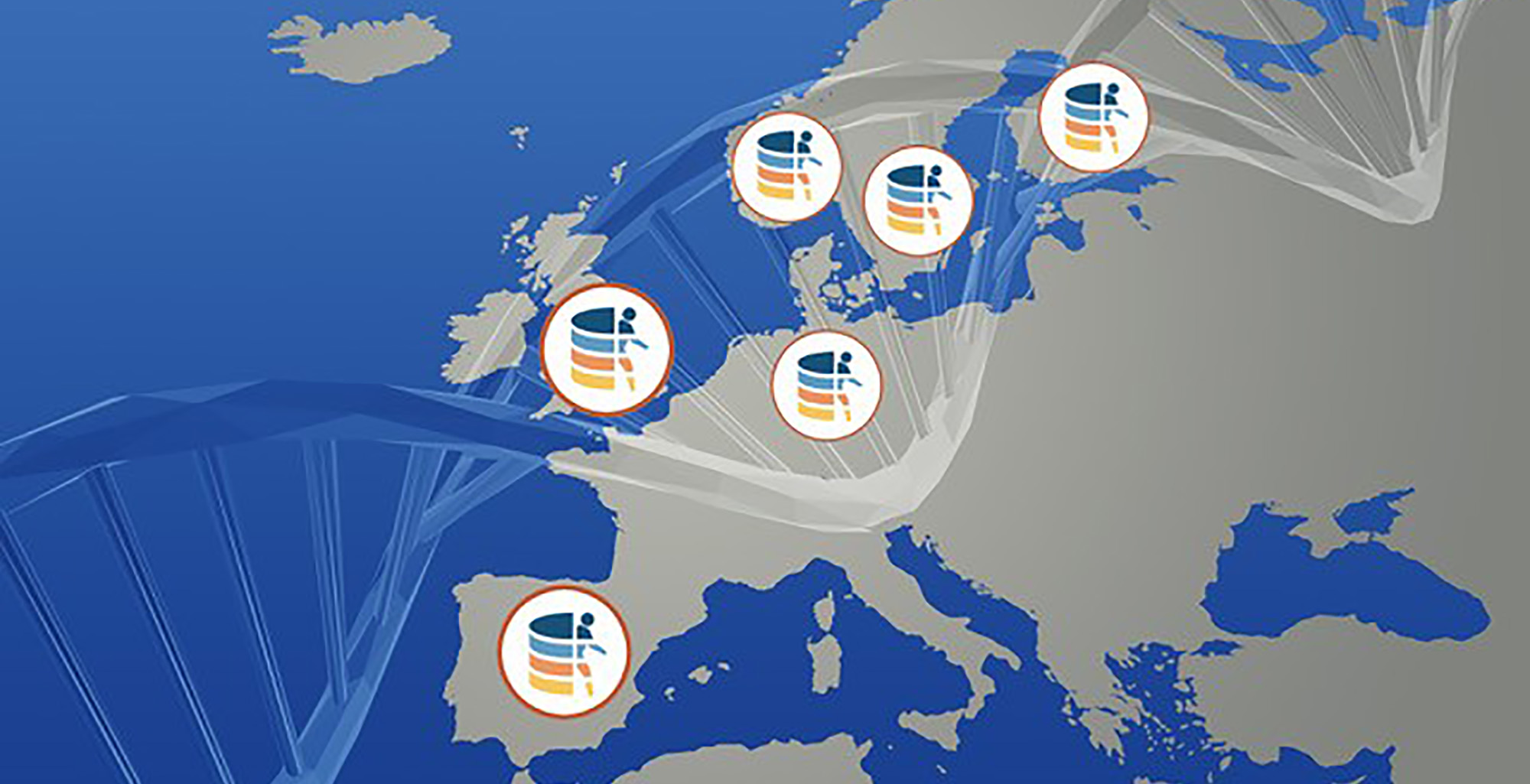
Ha nacido la Federación de Archivos Europeos de Genomas y Fenomas (FEGA), una infraestructura que facilitará el acceso a datos genómicos generados en cinco países – España, Alemania, Suecia, Finlandia y Noruega.
La FEGA proporciona una red que permite el acceso transnacional a datos genómicos humanos para la investigación, siguiendo con rigor las normativas de protección de datos, como la nueva ley GDPR. Así, la federación está formada por ‘nodos’ en institutos de investigación que almacenan y administran datos localmente y, a su vez, comparten los metadatos – la información sobre las características de cada conjunto de datos, como la étnia, la edad o el estado de salud de los participante en un estudio – para que los equipos científicos de todo el mundo descubran los datos y posteriormente puedan acceder a ellos y analizarlos de manera segura, sin que estos salgan del país donde se generaron.
Los datos del nodo español de EGA se albergarán en el supercomputador MareNostrum del Barcelona Supercomputing Center – Centro Nacional de Supercomputación (BSC-CNS), que será un componente clave en la estrategia de Medicina de Precisión del Sistema Nacional de Salud de España.
FEGA es una evolución del EGA, el Archivo Europeo de Genomas y Fenomas (lo que ahora sería el EGA central), que nació en el European Bioinformatics Institute (EMBL-EBI) en el Reino Unido y se amplió con la sede del Parque de Investigación Biomédica de Barcelona (PRBB) en 2013, gestionada por el Centro de Regulación Genómica (CRG).
Según Mallory Freeberg, coordinadora del EGA en el EMBL-EBI, este archivo “es como un motor de búsqueda seguro de datos genómicos, que ayuda a equipos científicos previamente autorizados a encontrar datos existentes sobre la enfermedad que están estudiando”.
Arcadi Navarro, director del equipo EGA en el CRG, está de acuerdo. “El objetivo de EGA es que cualquier investigador o investigadora pueda saber si existen estudios y datos de su interés, en cualquier lugar del mundo”.
El también profesor de investigación ICREA, profesor de la Universitat Pompeu Fabra (UPF) e investigador en el Instituto de Biología Evolutiva (IBE: CSIC-UPF) nos explica el porqué y el cómo de la ampliación de esta importante iniciativa.
Hasta ahora, el EGA recogía datos genómicos de proyectos de investigación de diferentes países de Europa – e incluso de otros lugares del mundo. ¿Por qué se ha ‘descentralizado’ y creado esta federación?
Hay tres motivos principales.
El motivo más importante es legal. Hasta ahora la mayoría de datos genómicos que teníamos, provenían de proyectos de investigación donde unas cuantas personas voluntarias participaban. Pero ahora – ya a día de hoy, y en un futuro cercano todavía más – tenemos más y más datos que provienen de los sistemas de salud. Cada vez es más común secuenciar el genoma de un paciente para determinadas pruebas de diagnóstico, por ejemplo. Y si estos pacientes acceden, estos datos pueden ser muy útiles para la investigación. Pero como el genoma no se puede anonimizar de forma absoluta (¡es único para cada persona!), son datos muy sensibles, por lo que cada país debe legislar qué hacer con estos datos y cómo. Y en algunos casos, esta legislación implica que los datos se deben custodiar dentro del propio país. Por lo tanto, aunque en EGA podamos tener datos que provengan de proyectos de investigación de Finlandia, por ejemplo, no podríamos tener datos del sistema de salud finlandés; estos se deberán gestionar y custodiar en una base de datos finlandesa.
«No hay manera de anonimizar completamente el genoma, por lo tanto, los datos genómicos son muy sensibles y requieren de un control muy regulado»
Arcadi Navarro (EGA-CRG, UPF, IBE)
¿Esto hace perder valor al EGA central?
No, de ninguna manera. Esta federación quiere decir que todos los datos están vinculados y, de hecho, se puede llegar a todos a través del EGA central. Es decir, a nivel de usuario, ni siquiera sabes de dónde vienen los datos. Tú entras en la web de EGA, buscas los conjuntos de datos que te interesan, y pides acceso, que obviamente está muy controlado. Este acceso estará gestionado primero por EGA central (a través del CRG y del EBI). A continuación, si los datos vienen de un proyecto de investigación, el acceso estará controlado por uno de los más de 1.500 comités de acceso a los datos propios de cada institución (algunas tienen un comité único para todos los datos que generan, otras tienen comités específicos para cada proyecto). Y si vienen de los sistemas de salud, salud o aquellos que lo requieran por el motivo que sea, el acceso estará gestionado por la sede local del propio país de origen.
Además, a todos nos interesa que los datos estén distribuidos y se gestionen desde diversos lugares, porque el EGA es un servicio gratuito pero muy costoso (aquí funciona gracias a las ayudas de la Fundación ‘la Caixa’ i el Instituto de Salud Carlos III). Y con lo que está creciendo, esta red hará que sea más sostenible. Por lo tanto, este es el segundo motivo para esta federación, un motivo práctico.
¿Y el tercer motivo?
El tercero es un motivo estratégico. Las personas que estamos gestionando el EGA vemos cada día los retos que esto supone, y también la grandísima importancia que tiene. Aunque hay miles de personas que lo utilizan, solo somos unas 60 (30 aquí y 30 en el Reino Unido) las que vemos esta realidad. ¡Ya nos va bien que haya muchas más personas en más instituciones viendo el problema desde dentro! Esto ayuda a crear consciencia, a que haya voces en diferentes países explicando a las autoridades, las agencias financiadoras, etc. que el compartir datos es una cuestión fundamental para que avance la ciencia, y que hay que invertir en ella.
“La ciencia es un proyecto de toda la humanidad”
Estos 5 países han sido los primeros de la federación. ¿Hay intención de ampliar a otros?
¡Claro que sí! Y no solo a países europeos. Ya nos han contactado desde Argentina, Canadá, Sudáfrica y Australia, diciendo que quieren ser parte de FEGA. Y si cumplen nuestros requisitos de fiabilidad, seguridad, calidad, etc. y siguen ciertos estándares para que los datos sean interoperativos y comparables con otros, estaremos encantados de que se unan.
Al final todos queremos lo mismo: generar más datos genómicos de todo el mundo (de diferentes poblaciones) y que éstos estén vinculados y accesibles al mayor nombre de investigadores e investigadoras, con el fin de avanzar más rápido en la prevención, el diagnóstico, el desarrollo de fármacos y nuevas terapias personalizadas… Porque la ciencia es un proyecto de toda la humanidad.