
El primer Data Science Meet-Up de l’Institut de Salut Global de Barcelona (ISGlobal), centrat en els biaixos en intel·ligència artificial, va tenir lloc el passat dimarts 23 de maig a la Sala Marie Curie, a la plaça interior del Parc de Recerca Biomèdica de Barcelona (PRBB). Aquestes trobades són una sèrie de xerrades mensuals híbrides, presencials i en línia, que tenen com a objectiu exposar diferents problemes de la ciència de dades i discutir solucions. Les trobades, organitzades pel grup de Ciència de Dades Biomèdiques liderat per Paula Petrone a ISGlobal, estan obertes a tota la comunitat del PRBB i més enllà, i també es retransmeten en directe. A més van seguides d’un refrigeri i la oportunitat per establir contactes.
Les trobades mensuals de ciència de dades estan obertes a tota la comunitat del PRBB i més enllà
En aquesta ocasió, l’amfitrió va ser Pablo Iáñez Picazo, recent estudiant de doctorat al grup. I el ponent convidat d’aquesta edició va ser Davide Cirillo, cap de la Machine Learning for Biomedical Research Unit al departament de ciències de la vida del Barcelona Supercomputing Center (BSC) – un centre de recerca que allotja un dels superordinadors més potents d’Europa, el MareNostrum.
Cirillo va tornar a visitar el PRBB anys després d’acabar el seu doctorat al Parc, al grup dirigit per Gian Gaetano Tartaglia, llavors al Centre de Regulació Genòmica (CRG). La seva investigació actual se centra en l’aplicació d’algorismes d’aprenentatge automàtic i ciència de xarxes per a la medicina de precisió, amb un gran èmfasi en l’ètica de la intel·ligència artificial (IA). Al seminari va parlar sobre les diferències i els biaixos de sexe i gènere en la IA per a la biomedicina i la salut.
Causes dels biaixos a la tecnologia
Abans de comprendre les causes dels biaixos, hem d’aclarir què són. Un biaix es pot definir a grans trets com un error que crea un desavantatge per a algunes persones. Hi ha innumberables biaixos i, com va esmentar Davide, sempre n’hi haurà; fins i tot se’n crearan de nous a mesura que es creïn noves tecnologies.
Els biaixos tecnològics poden estar relacionats amb procesos automàtics i analítics (i.e. el biaix estadístic). Però també hi ha biaixos deguts als éssers humans que estan darrere de la tecnologia: biaixos cognitius a nivell individual i biaixos culturals a nivell social. Tots aquests biaixos poden tenir altres atributs, com ser explícits o implícits, cosa que els fa molt més difícils de detectar. Però, com apareixen aquests biaixos a la IA?
Les dades s’utilitzen per entrenar models, que poden utilitzar-se per fer prediccions que tenen un impacte a la societat. Si les dades utilitzades estan esbiaixades, és probable que aquest impacte tingui conseqüències negatives per a algunes persones. Així, en la majoria de casos, el problema comença amb les dades. La recopilació de dades és, per tant, el primer aspecte en què cal enfocar-se.
“Lamentablement, vivim en un món on hi ha desigualtats i discriminació. Així que siguin quines siguin les dades que treiem d’aquest món, aquestes contindran rastres d’aquesta discriminació. I si es genera un model amb aquestes dades, el seu ús perpetuarà la discriminació”
Davide Cirillo (BSC)
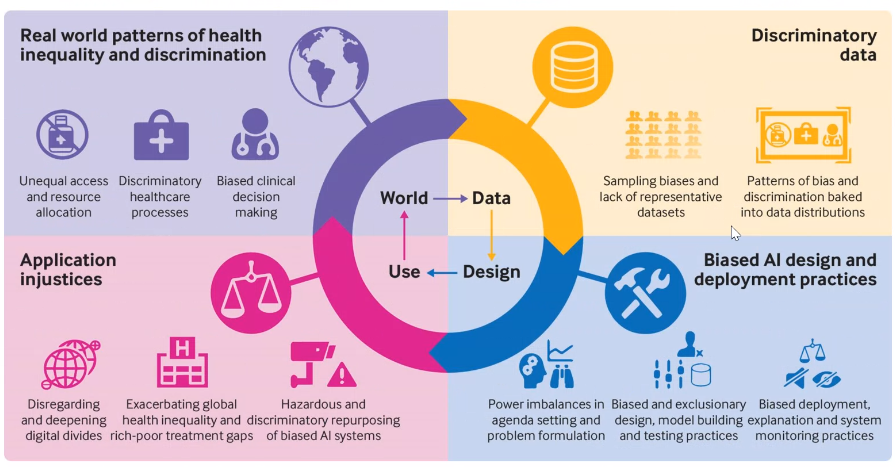
Què es pot fer per evitar-ho?
Les dades utilitzades per al desenvolupament de l’IA en biomedicina poden procedir de diferents llocs. Per exemple, un dels principals repositoris d’Europa és l’EGA (European Genome-Phenome Archive).
Per això en Davide i un grup d’investigadors al ELIXIR Biohackathon Europe van analitzar les metadades d’EGA per veure si les categories de gènere/sexe estaven ben reflectides en les dades recolectades. També van examinar dbGaP, l’homòloga nord-americana d’EGA. La comparació de les bases de dades nord-americana i europea va mostrar que a la primera s’informava molt menys del sexe biològic de les mostres recollides. Concretament, al repositori dels EUA, gairebé la meitat dels estudis tenien mostres de sexe desconegut; mentre que al repositori europeu la meitat de les mostres tenien una identificació clara de home/dona. Una indicació clara de la millora a nivell europeu va ser que, el 2018, EGA va fer obligatori indicar la categoria de sexe per totes les dades que s’hi registraven.
“Els recopiladors de dades i les bases de dades tenen un paper crucial a l’hora d’avaluar la classificació de les dades per sexe/gènere per evitar problemes més endavant”
A més de l’anàlisi de les metadades, en Davide i els seus col·legues van enquestar els participants del ELIXIR Biohackathon Europe, tots ells usuaris de repositoris de dades biomèdiques, sobre els seus coneixements en matèria de diversitat en la biomedicina. Tot i que tots estaven d’acord que era important incloure la diversitat, la majoria (67%) va dir no saber on trobar les directrius per fer-ho.
Així doncs, en Davide i els seus col·legues proposen ampliar els principis FAIR en l’administració de dades (segons els quals les dades han de ser Localitzables, Accessibles, Interoperables i Reutilitzables) afegint una lletra més: una X que indicaria que les dades també han de ser imparcials.
Per aconseguir aquestes dades FAIR-X, és essencial tenir una definició clara de sexe i gènere, i considerar el no binarisme; utilitzar els estàndards; garantir la transparència però també la preservació de la privacitat; i fomentar l’educació, l’impacte social i la implicació de les parts interessades.
L’any passat, en Davide i els seus companys i companyes van participar en la creació d’un document presentat al Parlament Europeu sobre possibles polítiques davant del biaix tecnològic en les bases de dades en biomedicina. El document proposava:
- No cal crear normatives específiques sobre aquest tema: ja s’està debatent la llei sobre la IA, i el tema del biaix s’hi hauria d’incloure (en aquesta i en qualsevol altra normativa)
- Enfocar-se en la recopilació de dades, per exemple, promovent la certificació de bases de dades per garantir que una font de dades determinada és imparcial.
- Ser transparent, especialment pel que fa a les persones de les quals procedeixen les dades.
Més enllà del sexe i el gènere – una multiplicitat de biaixos
Com s’esmentava al principi, hi ha molts tipus de biaixos més enllà del sexe/gènere, i per això necessitem una diversitat de dades quant a origen, edat, discapacitats,… totes aquestes, característiques que solen tenir biaixos lligats a elles. “Hi ha cadenes de biaixos, estan interrelacionats. La interseccionalitat és molt rellevant. Més enllà dels biaixos de sexe i el gènere, potser els biaixos racials són els més crítics, però també n’hi ha molts més”, admet Davide.
“Els biaixos estan interrelacionats i niats. La interseccionalitat és molt rellevant. Més enllà dels biaixos del sexe i el gènere, potser els biaixos racials són els més crítics, però també n’hi ha molts més“
Les normes i taxonomies o models de metadades són molt importants en aquest context, per a que les dades es puguin descriure correctament i utilitzar de forma justa. Però fins i tot si això es resolgués, continuarien existint altres reptes:
- Com es pot conciliar la presència d’informació sobre sexe, gènere, raça, etc. amb el dret de les persones a no revelar aquesta informació?
- Desagregar les dades per sexe o altres característiques implica acabar amb un conjunt de dades més petit, la qual cosa redueix el poder estadístic de l’estudi.
- El sexe no sols depèn dels cromosomes, sinó també de les hormones. Com gestionar els casos com les persones transsexuals sotmeses a tractament hormonal, o les persones intersexuals, en fer aquestes anàlisis?
Quan es tracta de la dimensió de sexe i gènere en l’anàlisis de dades, la recomanació general de Davide és fer un esforç per identificar possibles diferències de sexe i gènere, que podrien estar presents o no al conjunt de dades objecte d’estudi. “Però el truc és buscar-les activament, en cas contrari les passaràs per alt. Hi ha diferències que no veus si no les busques”, explica Davide.
Òbviament, comptar amb personal més divers en ciència i tecnologia també ajuda a detectar i mitigar aquests biaixos. “No podem eliminar els biaixos, però en podem ser més conscients“, conclou el ponent d’aquesta primera trobada de ciència de dades.
La propera trobada, el 21 de juny a les 13’30h, se centrarà en ChatGPT: aplicacions, limitacions, ètica i molt més. No us la perdeu!
Sobre l'autor/a Maruxa Martínez-Campos és biòloga. En acabar el doctorat a la Universitat de Cambridge es va passar a "l'altra banda" de la recerca. Va ser editora de Genome Biology i, durant gairebé dues dècades, va formar part del departament de comunicació del PRBB, on va liderar El·lipse com a editora en cap fins al 2025. També va coordinar el Grup de treball de bones pràctiques científiques i el Comitè d’Igualtat, Diversitat i Inclusió del PRBB.
Maruxa Martínez-Campos és biòloga. En acabar el doctorat a la Universitat de Cambridge es va passar a "l'altra banda" de la recerca. Va ser editora de Genome Biology i, durant gairebé dues dècades, va formar part del departament de comunicació del PRBB, on va liderar El·lipse com a editora en cap fins al 2025. També va coordinar el Grup de treball de bones pràctiques científiques i el Comitè d’Igualtat, Diversitat i Inclusió del PRBB.




