
El primer Data Science Meet-Up del Instituto de Salud Global de Barcelona (ISGlobal), centrado en los sesgos en inteligencia artificial, tuvo lugar el pasado martes 23 de mayo en la Sala Marie Curie, en la plaza interior del Parque de Investigación Biomédica de Barcelona (PRBB). Estos encuentros son una serie de charlas mensuales híbridas (presenciales y online), que tienen como objetivo exponer diferentes retos de la ciencia de datos y discutir soluciones. Los encuentros, organizados por el grupo de Ciencia de Datos Biomédicos liderado por Paula Petrone en ISGlobal, están abiertos a toda la comunidad del PRBB y más allá, y también se retransmiten en directo. Asimismo, van seguidos de un refrigerio y de la oportunidad para establecer contactos.
Los encuentros mensuales de ciencia de datos están abiertos a toda la comunidad del PRBB y más allá.
En esta ocasión, el anfitrión fue Pablo Iáñez Picazo, reciente estudiante de doctorado en el grupo. Y el ponente invitado fue Davide Cirillo, jefe de la unidad de Machine Learning for Biomedical Research, del departamento de ciencias de la vida del Barcelona Supercomputing Center (BSC) – un centro de investigación que alberga uno de los superordenadores más potentes de Europa, el MareNostrum.
Cirillo volvió a visitar el PRBB años después de terminar su doctorado en el Parque, en el grupo dirigido por Gian Gaetano Tartaglia, entonces en el Centro de Regulación Genómica (CRG). Su investigación actual se centra en la aplicación de algoritmos de aprendizaje automático y ciencia de redes para la medicina de precisión, con un gran énfasis en la ética de la Inteligencia Artificial (IA). En el seminario habló sobre las diferencias y sesgos de sexo y género en la IA en la biomedicina y la salud.
Causas de los sesgos en la tecnología
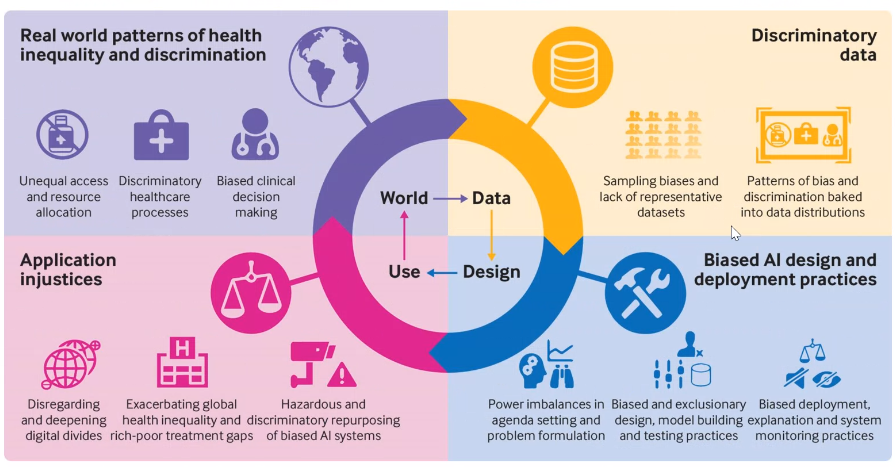
Antes de comprender las causas de los sesgos, debemos aclarar qué son. Un sesgo puede definirse a grandes rasgos como un error que crea una desventaja para algunas personas. Existen innumerables sesgos y, como mencionó Davide, siempre los habrá; incluso se crearán nuevos a medida que se creen nuevas tecnologías.
Los sesgos tecnológicos pueden estar relacionados con los procesos automáticos y analíticos (i.e. el sesgo estadístico). Pero también hay sesgos debidos a los seres humanos que están detrás de la tecnología: sesgos cognitivos a nivel individual y sesgos culturales a nivel social. Todos estos sesgos tienen distintos atributos, como el hecho que pueden ser explícitos o implícitos, lo que los hace mucho más difíciles de detectar. Pero, ¿cómo aparecen esos sesgos en la IA?
Los datos se utilizan para entrenar modelos, que pueden ser utilizados para hacer predicciones que tienen un impacto en la sociedad. Si los datos utilizados están sesgados, es probable que este impacto tenga consecuencias negativas para algunas personas. Por tanto, el problema empieza, en la mayoría de los casos, con los datos. La recopilación de datos es por eso el primer aspecto en el que hay que enfocarse.
“Lamentablemente, vivimos en un mundo en el que hay desigualdades y discriminación. Así que sean cuales sean los datos que saquemos de este mundo, estos contendrán rastros de esta discriminación. Y si se genera un modelo con estos datos, su uso perpetuará la discriminación”
Davide Cirillo (BSC)
Qué hacer para evitar o reducir los sesgos
Los datos utilizados para el desarrollo del aprendizaje automático en biomedicina pueden proceder de distintos lugares,. Por ejemplo, en Europa, uno de los principales repositorios de datos humanos es el EGA (European Genome-Phenome Archive).
Por eso Davide y un equipo de investigadores del ELIXIR Biohackathon Europe analizaron los metadatos de EGA para ver si las categorías de género/sexo estaban correctamente categorizadas. También examinaron dbGaP, la homóloga estadounidense de EGA. La comparación de las bases de datos estadounidense y europea mostró que en la primera se informaba mucho menos del sexo biológico de las muestras. Concretamente, en EE.UU., casi la mitad de los estudios tenían muestras de sexo desconocido, mientras que en el repositorio europeo la mitad de los datos tenían el género/sexo correctamente registrado. Una indicación clara de la mejora a nivel europeo fue que, en 2018, EGA hizo obligatorio indicar la categoría de sexo para todos los datos que se registraban.
“Las personas que recopilan datos y las bases de datos tienen un papel enorme en su clasificación por sexo/género, para evitar problemas a posteriori”
Además del análisis de los metadatos, Davide y sus colegas encuestaron a los participantes del ELIXIR Biohackathon Europe, todos ellos usuarios de repositorios de datos biomédicos, sobre sus conocimientos en materia de diversidad en biomedicina. Aunque todos estaban de acuerdo en que era importante incluir la diversidad, la mayoría (67%) dijo no saber dónde encontrar las directrices para hacerlo.
Así pues, Davide y colaboradores proponen ampliar el concepto de los principios FAIR en la administración de datos (según los cuales los datos deben ser Localizables, Accesibles, Interoperables y Reutilizables) añadiendo una letra más: una X que indicaría que los datos también deben ser imparciales.
Para obtener estos datos FAIR-X, es esencial tener una definición clara de sexo y género y considerar el no binarismo); utilizar estándares; asegurar la transparencia pero también preservación de la privacidad; y fomentar la educación, el impacto social y la implicación de las partes interesadas.
El año pasado, Davide y sus compañeros y compañeras participaron en un documento presentado al Parlamento Europeo sobre posibles políticas frente al sesgo tecnológico en biomedicina. El documento proponía:
- No crear más normativas al respecto: ya se está debatiendo la ley sobre IA, y el tema del sesgo debería incluirse en ella (y en todas las demás).
- Enfocarse en la recopilación de datos, por ejemplo, promoviendo la certificación de bases de datos para garantizar que una fuente de datos es imparcial.
- Ser transparente, especialmente en lo que respecta a las personas de las quales proceden los datos.
Más allá del sexo y el género– una multiplicidad de sesgos
Como se mencionaba al principio, hay muchos tipos de sesgos más allá del sexo/género, y necesitamos una diversidad de datos en cuanto a origen, edad, discapacidades,… todas estas características que suelen tener sesgos ligados a ellas. “Hay cadenas de sesgos, están interrelacionados. La interseccionalidad es muy relevante. Más allá del sesgo de sexo y género, quizá el sesgo racial sea el más crítico, pero hay muchos más”, admite Davide.
“Los prejuicios están interrelacionados. La interseccionalidad es muy relevante. Más allá del sesgo de sexo y género, quizá el sesgo racial sea el más crítico, pero hay muchos más”
Las normas y taxonomías o modelos de metadatos son muy importantes en este contexto, para que los datos se puedan describir correctamente y utilizar de forma justa. Pero incluso si eso se resolviera, seguirían existiendo otros retos:
- ¿Cómo conciliar la presencia de información sobre sexo, género, raza, etc. con el derecho de las personas a no revelar esta información?
- Desagregar los datos por sexo u otras características implica acabar con un conjunto de datos más pequeño, reduciendo el poder estadístico del estudio.
- El sexo no sólo depende de los cromosomas, sino también de las hormonas. Al realizar estos análisis, ¿Cómo gestionar los casos como las personas transexuales sometidas a tratamiento hormonal, o las personas intersexuales, al realizar estos análisis?
Cuando se trata de discriminación de sexo o género en el anàlisis de datos, la recomendación general de Davide es hacer un esfuerzo por identificar posibles diferencias de sexo y género, que podrían estar presentes o no en el conjunto de datos objeto de estudio. “Pero el truco está en buscarlas activamente, de lo contrario las pasarás por alto. Hay diferencias que no ves si no las buscas”, explica Davide.
Obviamente, contar con un personal más diverso en ciencia y tecnología ayuda a detectar y mitigar estos sesgos. “No podemos eliminar los sesgos, pero podemos ser más conscientes de ellos”, concluye el ponente de este primer encuentro de ciencia de datos.
El próximo encuentro, el 21 de junio a las 13’30h, se centrará en ChatGPT: aplicaciones, limitaciones, ética y mucho más. ¡No os lo perdáis!





