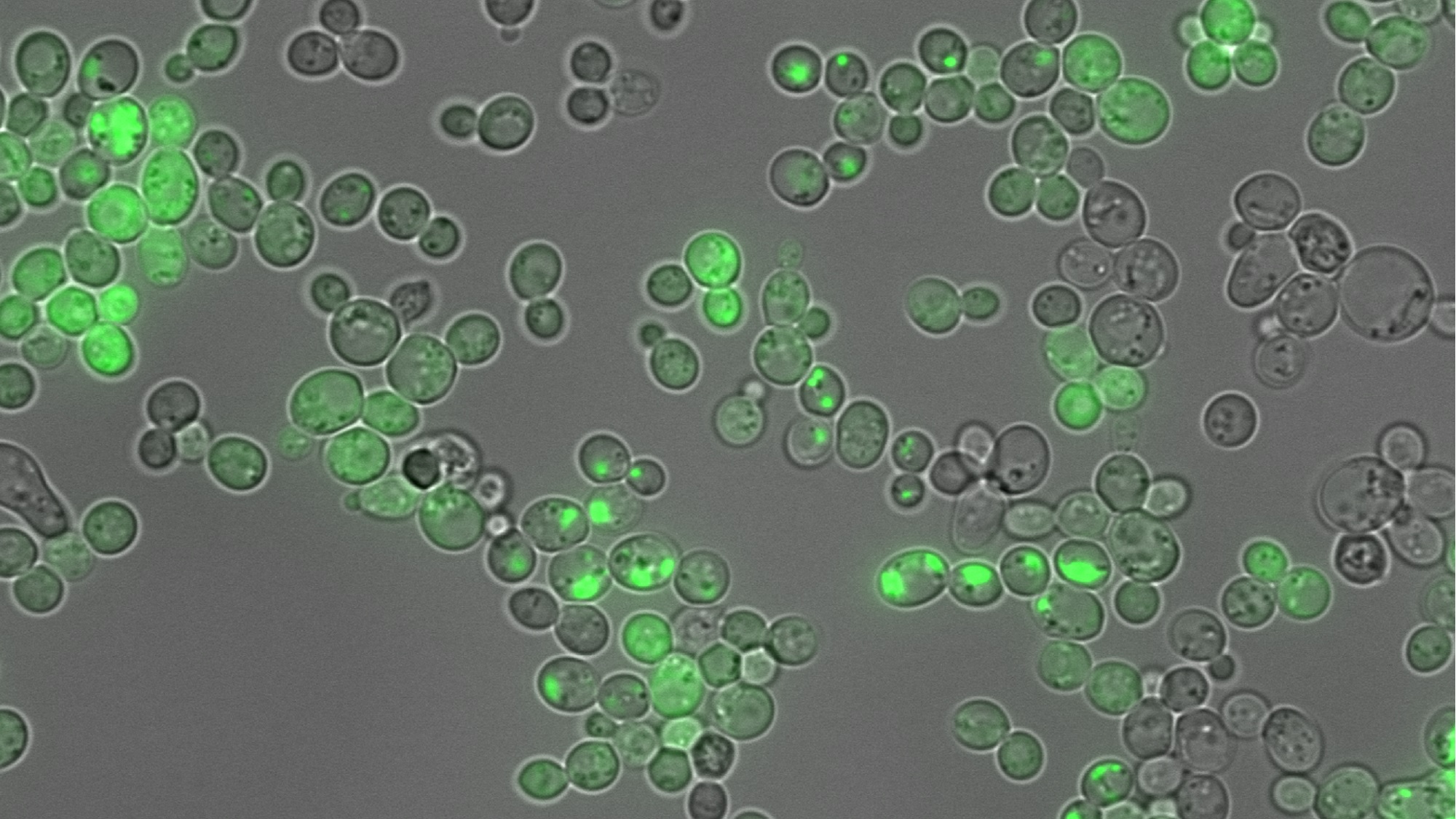
En un gran avance científico, equipos investigadores han desarrollado una nueva herramienta de Inteligencia Artificial, llamada CANYA, que puede descodificar el «lenguaje» que utilizan las proteínas para formar agregados nocivos, un proceso implicado en enfermedades como el Alzheimer y docenas de otros trastornos. CANYA permite a los científicos ver exactamente qué combinaciones de aminoácidos (los bloques de construcción de las proteínas) fomentan o impiden la agrupación de proteínas conocida como agregación amiloide, que puede alterar la función celular normal.
Los investigadores han sido liderados por Benedetta Bolognesi (Instituto de Bioingeniería de Cataluña (IBEC)) y Ben Lehner (Centro de Regulación Genómica (CRG) y Wellcome Sanger Institute), en colaboración con científicos del Cold Spring Harbor Laboratory (CSHL).
Para construir CANYA, el equipo creó el conjunto de datos más grande sobre la agregación de proteínas, generando más de 100.000 fragmentos de proteínas completamente aleatorios, incluidas muchas versiones que no se encuentran en la naturaleza. Después introdujeron cada fragmento en células de levadura para comprobar su comportamiento. Este enfoque innovador les dio una visión mucho más amplia de los comportamientos potenciales de las proteínas que otros estudios que sólo analizan conjuntos naturales o pequeños de secuencias.
Los datos se utilizaron para entrenar a CANYA mediante una combinación de métodos de IA extraídos del reconocimiento de imágenes y del reconocimiento del lenguaje. Estos dos mecanismos permiten al sistema ampliar los pequeños detalles de las cadenas de proteínas y al mismo tiempo entender su importancia en un contexto más amplio. Como resultado, CANYA no sólo predijo si una proteína formaría agregados, sino que también explicó el por qué, revelando nuevas reglas sobre cómo se comportan las proteínas.
Aplicación en desarrollo de fármacos
La importancia de este trabajo se extiende más allá de la investigación de enfermedades. La agrupación de proteínas es un reto importante en la biotecnología, especialmente en la fabricación de fármacos basados en proteínas, que pueden convertirse en inutilizables si éstas se agregan. La capacidad de CANYA para identificar secuencias propensas a la agregación podría ayudar a los ingenieros e ingenieras a diseñar proteínas más estables, ahorrando tiempo y dinero.
Aunque actualmente la herramienta clasifica las proteínas en tipos con o sin tendencia a agruparse, los investigadores pretenden ampliarla para predecir la rapidez con que se agregan las proteínas, un factor clave en la progresión de las enfermedades neurodegenerativas.
La importancia de la transparencia en IA
A diferencia de los típicos sistemas de IA que producen resultados sin que se sepa muy bien cómo (la famosa «caja negra»), CANYA es «explicable«, es decir, fue construida específicamente para revelar las reglas químicas que hay detrás de sus decisiones, haciéndolas transparentes y comprensibles para los humanos. «Queremos poder confiar en que el modelo está haciendo sus predicciones por razones que tienen sentido, y no en base a algo que simplemente se correlaciona con el resultado pero que en realidad no está en absoluto relacionado con él, como podría suceder en una IA de ‘caja negra'», explica Mike Thompson, primer autor del artículo.
«A medida que más y más investigadores e investigadoras recurren a la IA para analizar y modelar sus datos, es fundamental comprender las conclusiones y predicciones hechas por el modelo»
Mike Thompson (CRG), primer autor del artículo
Al preguntarle sobre los desafíos de hacer que la IA sea explicable, Thompson dice: «No es tan difícil para los contextos biológicos, pero generalmente conlleva el riesgo de una pérdida de poder predictivo. Esto se debe a que cuanto más compleja es la arquitectura del modelo – cuantos más parámetros utiliza – mejor rinde, pero también menos entendemos cómo funciona».
Aunque hacer que CANYA fuera explicable significaba sacrificar un poco de su poder predictivo, valió la pena para mejorar su confiabilidad. Además, la herramienta demostró ser un 15% más precisa que los modelos existentes.
Los autores esperan que este trabajo sirva como ejemplo de formas de seleccionar e interpretar arquitecturas de los modelo predictivos, y están explorando otros escenarios y guías para desarrollar estas prácticas.
En definitiva, este estudio demuestra cómo la combinación de experimentos de laboratorio a gran escala con IA explicable puede hacer que la biología sea más predecible, un paso esencial para las innovaciones tanto en salud como en biología sintética.
Mike Thompson, Mariano Martín, Trinidad Sanmartín Olmo, Chandana Rajesh, Peter K. Koo, Benedetta Bolognesi, Ben Lehner. “Massive experimental quantification allows interpretable deep learning of protein aggregation“. Science Advances, 30 Apr 2025, Vol 11, Issue 18. DOI: 10.1126/sciadv.adt5111